데이터베이스 I/O와 스캔 메커니즘
학부생인 아는 분이랑 온라인 스터디 같이 하다가 나눈 얘기가 있습니다.
그분이 학교 축제에 츄가 왔는데, 츄가 본인을 보면서 환하게 웃어줬다면서 너무 좋아하시는 거예요.
거의 뭐 사랑에 빠진 것처럼 푹 빠져있으시길래 제가 얘기해 드렸죠.
그거 츄가 님을 인덱스 스캔한 게 아니라 풀 테이블 스캔 하는 중이었는데 마침 님이 그 테이블에 있었던 거라고.
인트로에 쓸 말이 없어서 쓸데없는 얘기 좀 해봤고요.
그런 의미에서 이번 포스트에서는 데이터베이스의 I/O 작업과 데이터 스캔 메커니즘에 대해 알아보도록 하겠습니다.
# 00. 데이터베이스 저장 구조
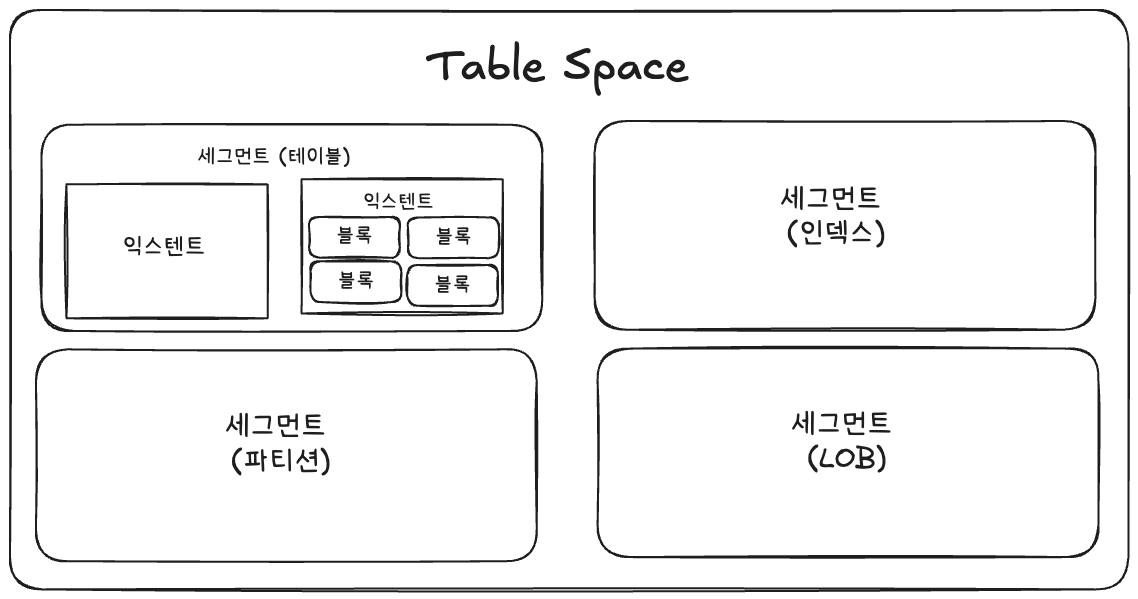
먼저 I/O와 스캔 방식에 대해 알아보기 전에 데이터베이스의 데이터 저장 구조에 대해 알아볼 필요가 있습니다.
데이터베이스가 디스크 위에 데이터를 배치하는 구조를 크게 네 개의 계층으로 구분해서 볼 수 있습니다.
테이블스페이스
테이블스페이스는 어떤 세그먼트를 담을지 정의하는 논리적인 공간입니다.
하나의 스페이스에는 여러 개의 테이블 세그먼트, 여러 개의 인덱스 세그먼트 등 여러 세그먼트가 존재합니다.
또한 하나 이상의 데이터파일로 구성되어 물리적 매핑의 역할을 합니다.
세그먼트
세그먼트는 테이블, 인덱스와 같이 데이터 저장공간이 필요한 오브젝트입니다.
일반적으로 파티션 구조가 아니라면, 하나의 테이블은 하나의 세그먼트라고 볼 수 있습니다.
하나의 세그먼트는 여러 개의 익스텐트로 이루어져 있습니다.
익스텐트
익스텐트는 테이블, 인덱스 등의 공간을 확장하는 단위입니다.
테이블에 쓰기 작업을 계속하면서 공간이 부족해지면, 테이블스페이스로부터 새로운 익스텐트를 할당받습니다.
익스텐트는 여러 개의 블록들로 이루어져 있습니다.
블록(Page)
블록은 I/O의 기본 최소 단위이며, 한 블록은 하나의 테이블에 대한 데이터가 독점합니다.
이는 테이블 하나의 모든 데이터가 하나의 블록에 있음을 의미하는 게 아니라, 하나의 블록 안에는 하나의 테이블에 대한 데이터들로만 이루어져 있음을 의미합니다.
또한 블록이 I/O의 기본 최소 단위라는 말은 특정 레코드 하나를 읽고 싶으면 그 레코드에 해당하는 블록 전체를 읽어야 함을 의미합니다.
익스텐트를 이루고 있는 블록은 물리 디스크상에서 인접한 공간에 있습니다.
하지만 세그먼트의 두 익스텐트끼리는 서로 바로 붙어있을 필요가 없는데 이 점을 유의해주셔야 합니다.
각 계층들과 데이터파일 간의 관계도 알아둘 필요가 있습니다.
세그먼트 공간이 부족해지면 테이블스페이스로부터 익스텐트를 추가로 할당받는다고 했는데, 세그먼트에 할당된 모든 익스텐트가 같은 데이터파일에 위치하지 않을 수 있습니다.
다시 말해 같은 세그먼트의 익스텐트들이라도 데이터가 다른 데이터파일에 위치하게 될 수도 있음을 의미합니다.
이렇게 하나의 테이블스페이스를 여러 데이터파일로 구성함으로써 파일 경합을 줄일 수 있게 됩니다.
# 01. Sequential Access vs Random Access
시퀀셜 액세스
시퀀셜 액세스는 논리적 또는 물리적으로 연결된 순서에 따라 차례대로 블록을 읽는 방식입니다.
인덱스 리프 블록의 경우 앞뒤를 가리키는 주소값을 통해 서로 논리적으로 연결되어 있기 때문에 이를 통해 순차적으로 스캔이 가능합니다.
반면, 테이블 블록 간에는 서로 논리적인 연결 고리가 없습니다.
세그먼트는 할당된 익스텐트 목록을 세그먼트 헤더에 맵으로 관리하는데, 이 익스텐트 맵이 각 익스텐트의 첫 번째 블록 주소값을 가지기 때문에 이를 활용해서 테이블 블록에 대해 시퀀셜 액세스가 가능합니다.
랜덤 액세스
랜덤 액세스는 논리적, 물리적인 순서를 따르지 않고, 레코드 하나를 읽기 위해 한 블록씩 접근하는 방식입니다.
# 02. Single Block I/O vs Multi Block I/O
Single Block I/O
캐시에서 찾지 못한 데이터 블록을 디스크에서 DB 버퍼캐시로 적재할 때 한 번에 한 블록씩 가져오는 방식을 Single Block I/O라고 합니다.
인덱스를 이용할 때는 기본적으로 인덱스와 테이블 등록 모두 Single Block I/O 방식을 사용합니다.
Multi Block I/O
데이터 블록을 디스크에서 DB 버퍼캐시로 적재할 때 한 번에 인접한 블록들까지 한 번에 요청해서 메모리에 적재하는 방식을 Multi Block I/O라고 합니다.
많은 데이터 블록을 읽을 때 효율적이며 그러한 이유로 인덱스를 이용하지 않고 테이블 전체를 스캔할 때 이 방식을 사용합니다.
I/O는 성능을 저하시키는 느린 동작입니다.
대용량 테이블의 경우 수많은 블록을 디스크에 읽는 동안 매번 Single Block I/O 방식으로 읽어 들인다면, I/O call 횟수가 많아져 성능이 크게 저하될 수밖에 없습니다.
때문에 대용량 테이블을 Full Scan 할 때는 Multi Block I/O를 사용하며, 단위를 크게 설정하여 성능을 높여야 합니다.
# 03. Table Full Scan vs Index Range Scan
Table Full Scan
말 그대로 테이블에 속한 블록 전체를 읽어서 사용자가 원하는 데이터를 찾는 방식입니다.
Sequential Access와 Multi Block I/O 방식으로 디스크 블록을 읽으며, 한 블록에 속한 모든 레코드를 한 번에 읽어 들이고, 캐시에서 못 찾으면 '한 번의 수면(I/O Call)을 통해 인접한 수십~수백 개 블록을 한꺼번에 I/O 하는 메커니즘입니다.
한 번에 전체 블록을 읽어 들이는 방식이 Index Range Scan보다 대부분의 상황에서 좋을 거라는 생각이 들 수도 있지만, 소량의 데이터를 찾을 때 수백만~수천만 건 데이터를 스캔하는 것은 비효율적입니다.
Index Range Scan
Random Access와 Single Block I/O 방식으로 디스크 블록을 읽어오는 방식입니다.
다시 말하면, 캐시에서 블록을 찾지 못하면, 매번 레코드 하나를 읽기 위해 I/O Call이 일어나는 메커니즘이라고 보실 수 있습니다.
따라서 많은 데이터를 읽을 때는 Table Full Scan에 비해 성능이 안 좋을 수 있으며, 같은 블록에 대해 여러 번 액세스 하는 경우도 있기 때문에 비효율이 발생할 수 있습니다.
개발 공부하는게 너무 즐겁긴 하지만 아직 갈 길이 한참 멀고 ... 좀 일찍 시작했으면 정말 좋았겠다 싶기도 하고요.
다들 화이팅